信息摘要:
小麦粉是国民摄入营养物质的主要载体,其品质检测工作繁琐且重要。小麦粉中水分、灰分和面筋的含量不仅影响小麦粉的口感,更影响小麦粉的品质。目前小麦粉生产厂家主要使用...
小麦粉是国民摄入营养物质的主要载体,其品质检测工作繁琐且重要。小麦粉中水分、灰分和面筋的含量不仅影响小麦粉的口感,更影响小麦粉的品质。目前小麦粉生产厂家主要使用传统国标手段检测小麦粉中水分、灰分和面筋含量,费时费力且人工成本高。近年来,小麦粉安全事件频繁发生,揭示了小麦粉品质检测存在的问题和漏洞,凸显了对小麦粉品质进行高效准确检测的重要性[1]。虽然许多研究人员都提出了可行的方法来实现对小麦粉成分含量的无损、快速、准确检测,但大都停留在验证模型的可行性与可靠性方面,模型的稳健性和实际应用效果仍有提高空间。因此研究出一种具有高准确度和高稳健性的定量分析模型刻不容缓。
近年来,近红外光谱(Near infrared spectroscopy,NIR)技术随着科学技术的发展广泛应用在各领域[2][3][4]。其波长范围在780~2526 nm。由于在这个区间内,反映的信息包括氢元素化学键(如O—H、C—H)分子振动的信息吸收状态,所以近红外光谱的分析对象基本上可以涵盖所有的有机化合物。同时,近红外光谱还拥有很高的穿透性能,可用于分析液态、固态和粉末状样品等多种物态的物质[5][6]。目前,近红外光谱技术已经较为成熟,以其快速、高效、低成本的特点,广泛应用于以农业为主的多个领域。在对农业作物中所含蛋白质、水分、糖类及其他营养物质的定量检测方面取得了一定成果。
在小麦粉品质定性或定量检测分析中,近红外光谱技术也取得了较好的效果。金华丽等[7][8]验证了近红外光谱技术测定小麦粉水分含量和灰分含量的可行性和可靠性。赵环[9]采用近红外光谱技术结合特征提取算法,实现了对小麦粉蛋白质含量的无损检测。闫李慧[10]采用近红外光谱技术结合多种建模方法对面粉水分、灰分、蛋白质含量等品质指标进行了定量预测。在目前的研究中,基于近红外光谱技术的小麦粉品质定量检测虽然取得了较好的准确性[11],但对近红外光谱存在的信息重复、背景噪声等问题缺乏进一步的分析。对于模型本身的分析与优化较少,也缺乏对所选的样本划分、预处理和特征提取算法的比较分析。
鉴于此,本研究采用了基于近红外光谱技术建立小麦粉品质偏最小二乘定量快速检测模型。选择了3种样本划分方法、8种光谱预处理算法和3种特征波长筛选算法进行组合,并分析比较了不同数据处理方法对模型精度的影响。通过进一步优化模型,提升模型整体预测能力和稳健性,实现了对小麦粉中水分、灰分和面筋的定量检测。这为小麦粉品质的快速检测提供了技术支撑。
1 材料与方法
1.1 材料
实验小麦粉样本全部取自不同生产日期、不同批次以及不同种类的小麦粉产品。
小麦粉待测组分的化学真值均由检验人员按照国标法测得,分别按照水分、灰分和湿面筋3种组分浓度梯度选择实验样本,尽量保证实验样本组分含量均匀分布且具有代表性。实验样本共83份,选取其中66份样本作为校正集,17份样本作为测试集。样本水分、灰分、湿面筋(以下简称为面筋)3种组分的含量特性如表1所示。
表1 小麦粉样本各组分含量
1.2 仪器
近红外光谱仪:,波长范围为1150~2150 nm,分辨率设置为12.5 nm。
1.3近红外光谱采集
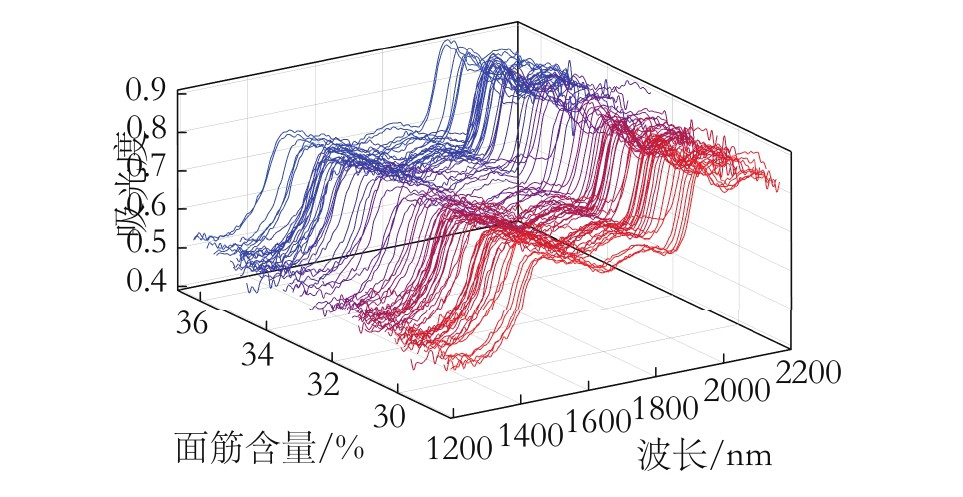
图1 小麦粉近红外光谱
实验模拟了在线近红外检测系统,采集到小麦粉样本近红外光谱图。由图1可知,小麦粉的近红外光谱区重叠严重,很难提取出与成分含量相关的信息,特别是面筋的含量较为离散,故图1以面筋含量为例。因此需要进行光谱预处理以及波长筛选。
1.4 数据处理
1.4.1 样本划分
分别采用随机选取(Random selection,RS)法、Kennard Stone (KS)法和SPXY(Sample set partitioning based on joint X-Y distance)法对样本进行划分,分析不同样本划分法对小麦粉品质检测模型的影响[。
1.4.2 数据预处理
近红外光谱数据中除了有效特征信息外,还存在重复信息和背景噪声。在建模前对光谱数据进行合理的预处理能有效降低冗余信息和噪声对光谱的干扰,提高光谱分辨率,提高模型的预测性能和鲁棒性[18]。
本研究分别采用数据中心化法(Data Centralization)、归一化法(Normalization)、移动窗口平滑法(Moving window smoothing,MWS)、卷积平滑法Savitzky-Golay(S-G)、多元散射校正法(Multiplicative Scatter Correction,MSC)、标准正态变量交换法(Standard Normal Variate,SNV)、一阶导数(First derivative,1-der)和二阶导数(Second derivative,2-der)这8种预处理方法对光谱数据进行处理。通过对比不同预处理方法的建模结果,找到最佳的预处理方法。由于导数运算对高频噪声非常敏感,很可能增大高频误差,因此在进行导数运算之前进行平滑处理。本研究在Python3.9环境下完成数据预处理。
1.4.3 特征波长筛选
经过样本划分和预处理后,在模型中引入连续投影算法[19](Successive projection algorithm,SPA)、竞争自适应重加权法[20](Competitive adaptive reweighted sampling,CARS)和蒙特卡罗无信息变量消除法[21](Monte carlo uninformative variable elimination,MCUVE)这3种特征波长筛选算法,进一步剔除冗余信息,提高模型精度]。
SPA算法是一种正向循环波长变量选取方式,通过计算向量的投影来找到一组具有最小冗余信息的变量集合。该方式能有效消去变量间的奇异性、共线性和不定性,最小化向量间的共线性。SPA算法可以对没有信息的波长和共线性高的波长进行剔除和降重,提高模型的稳定性,减少模型的计算量,在波长的选择中得到广泛的实践与使用。
CARS方法基于达尔文进化论的优胜劣汰准则,把波长点作为个体逐步淘汰,可广泛应用于基因组或代谢组数据等各种类型的变量选择,有效去除非信息点,同时压缩共线变量。CARS方法利用化学意义上的一些关键波长进行预测,而不是单个连续波段或多个连续波段的组合。采用指数衰减函数和自适应重加权采样来选择模型中的最佳特征子集,从而提升了模型的分析结果,取得了很好的预测效果。
MCUVE方法融合了蒙特卡罗采样法与无信息变量消除算法,充分考虑了样品间的内在有关信息。通过计算回归系数每列的均值和标准差,将它们的商作为变量可靠度的值,将变量按所对应的可靠度进行排列,去除一部分可靠度较低的无效变量,进而减少建模变量的数量以及模型复杂度,提高结果的准确性。
1.4.4 技术路线
偏最小二乘法(Partial least squares,PLS)是在光谱数据分析中常用的方法。本研究采用PLS算法进行建模,将数据处理过程分为样本划分、数据预处理以及特征提取等3个步骤。处理后的数据依次输入模型,以对比不同处理方法的建模效果。数据分析与处理、模型建立和图片生成均在Python 3.9环境下进行,采用Pycharm软件完成。
2 结果与分析
2.1 小麦粉样本划分
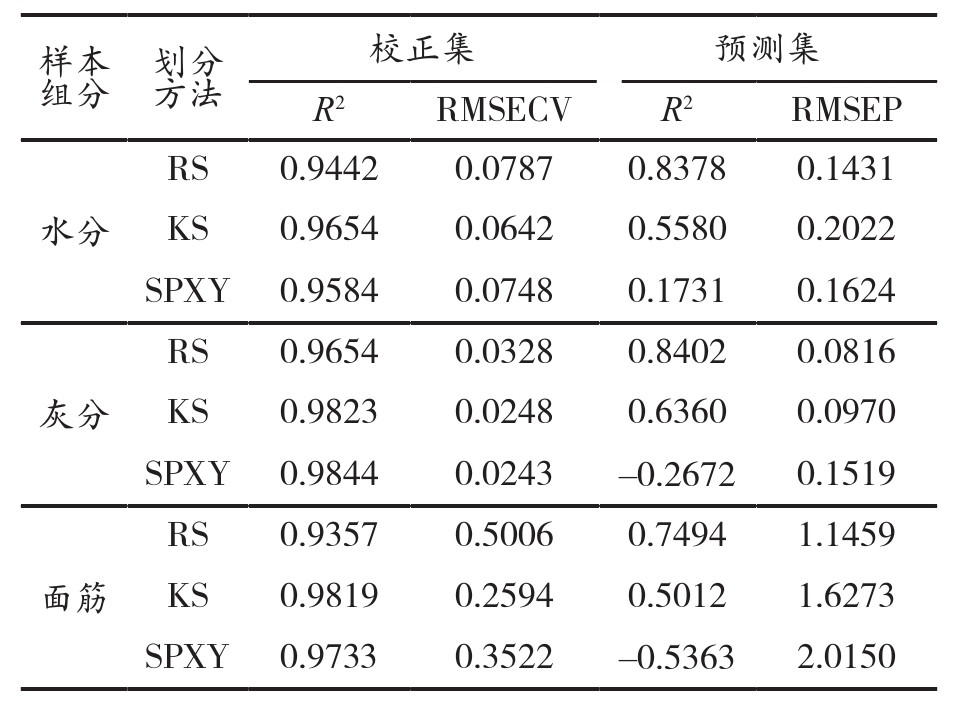
在Python3.9环境下,分别使用RS法、KS法和SPXY法对83个小麦粉样本进行划分,并采用PLS建立模型。小麦粉水分、灰分和面筋的PLS模型结果如表2所示。
表2 不同样本划分方法的建模结果
由表7可知,采用RS法进行样本划分的效果最好。利用划分后的数据集直接建模,3种组分预测集的R2均高于KS法和SPXY法。采用其余2种方法时,校正集的结果较好,相比与RS法,R2提升了1.75%~4.94%,RMSECV降低了4.96%~48.18%,但是预测集的结果较差,RMSEP反而增大。这种现象可能是由于样本的3种组分的数值波动范围较小,使得KS法和SPXY法选择的样本过于集中,未能充分考虑吸光度和各组分含量真值的分布,导致出现过拟合。
2.2 数据预处理
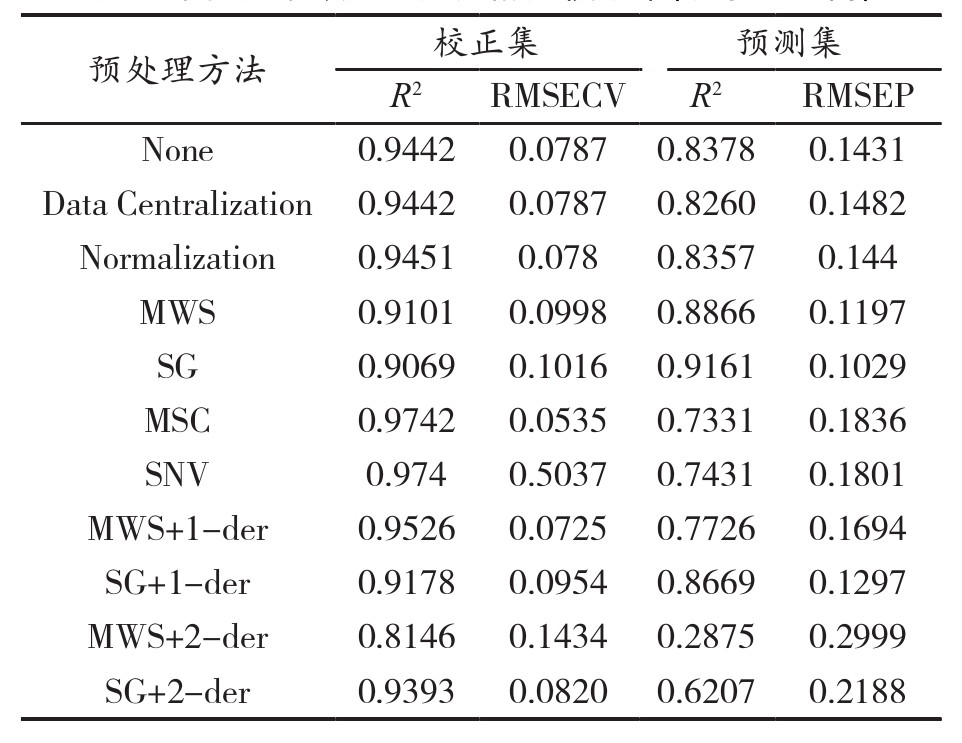
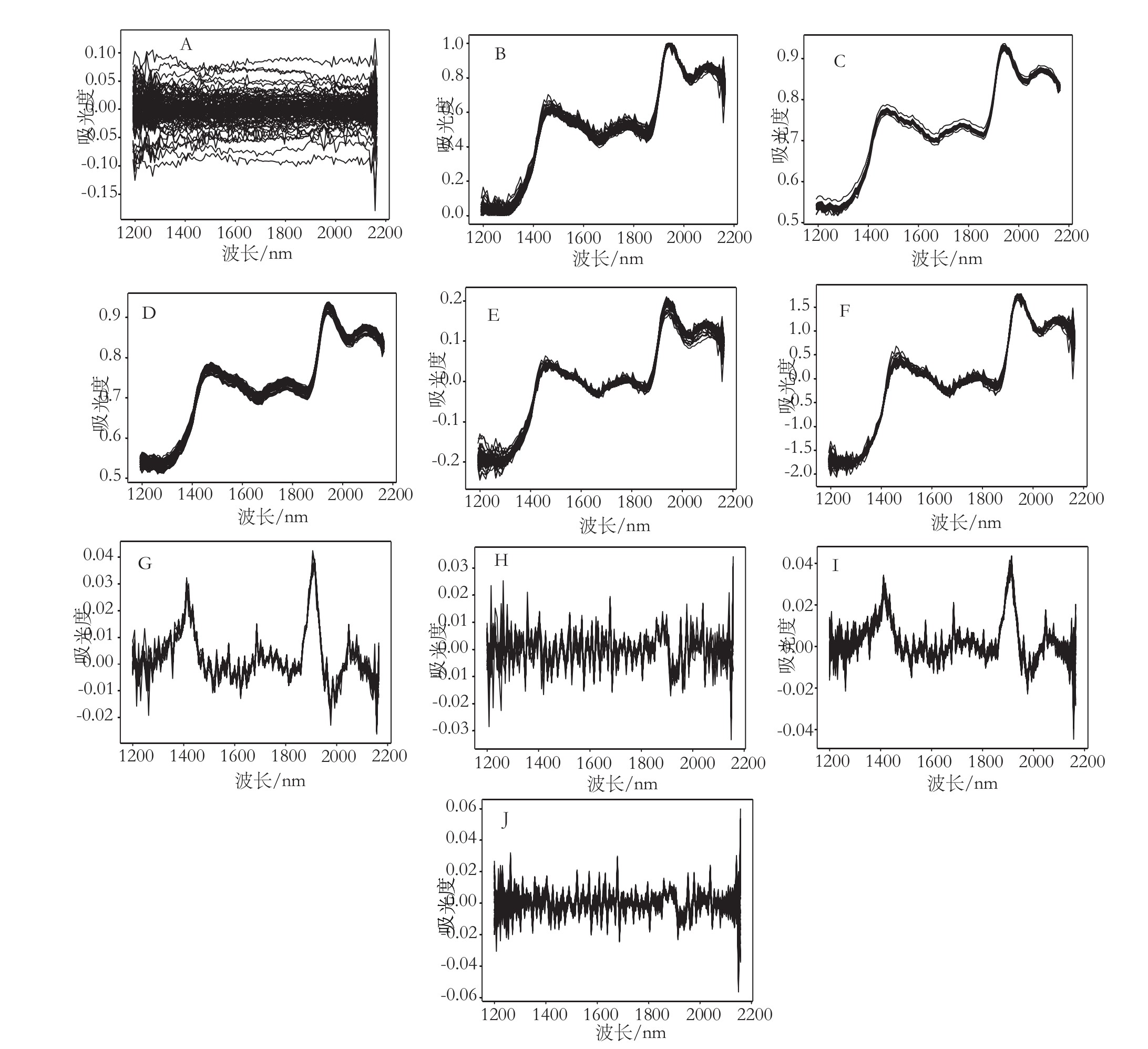
选择不同的光谱预处理方法会对模型的性能产生影响。采用中心化、归一化、移动窗口平滑、S-G平滑、多元散射校正、标准正态变量变换、一阶和二阶导数运算等方法对小麦粉谱图进行预处理,建立水分、灰分、面筋3种组分的含量预测模型。小麦粉原始光谱和经不同预处理方法处理后的光谱如图2A~图2J所示。
下面以小麦粉水分含量为例,应用不同光谱预处理方法处理光谱后,对小麦面粉水分含量建立PLS模型。由表3可知,结果显示,对于小麦粉水分,建模效果最好的是SG平滑,其RMSEP最小的同时,预测集相关系数R2较好且并不明显高于校正集,预测集的R2为0.9161,RMSEP为0.1029。观察图像也可发现,经SG平滑预处理后的谱图吸收峰更加清晰。
表3 不同光谱预处理方法的建模结果(以水分为例)
对于小麦粉灰分和面筋,在不同预处理方法中,建模效果最好的分别是一阶导数结合SG平滑和归一化法。预测集的R2分别为0.8718和0.7609,RMSEP分别为0.0731和1.1194。
2.3 特征波长筛选
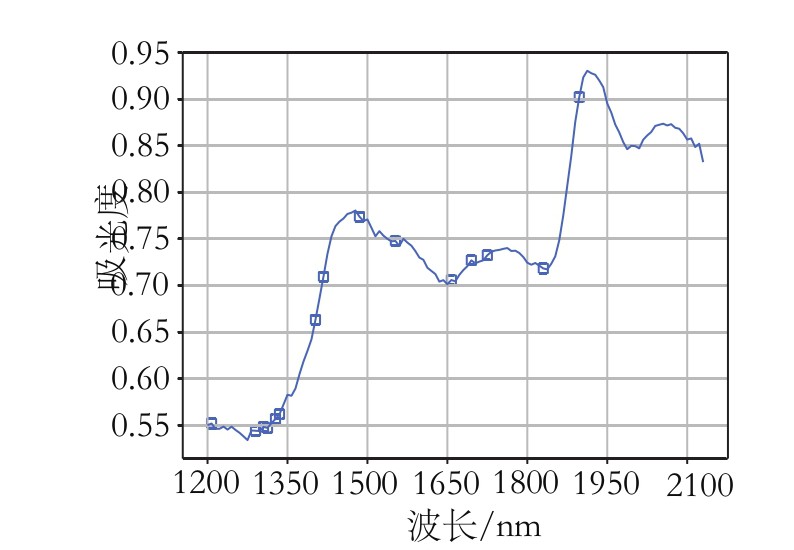
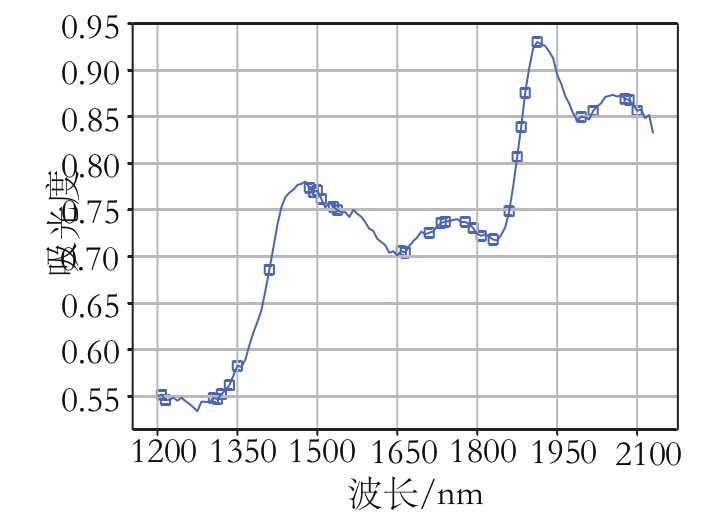
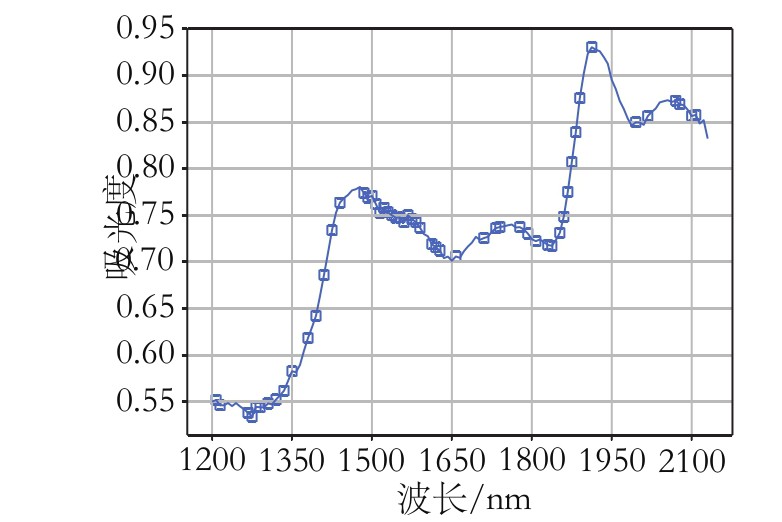
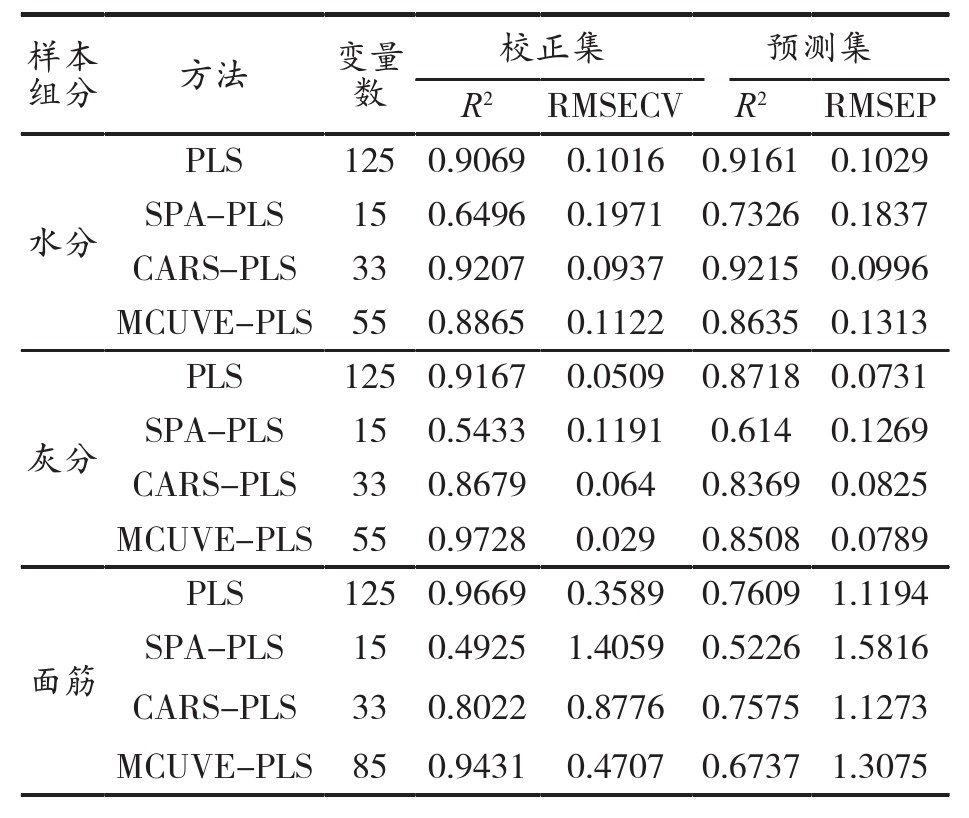
针对3种组分的样本划分方法和预处理方法已经确定,对模型分别使用SPA、CARS和MCUVE3种特征提取算法,提取近红外光谱的特征波长,建立小麦粉水分、灰分、面筋3种组分的模型。以小麦粉水分含量模型为例,采用SG-CARS-PLS算法的模型精度最高。小麦粉水分含量模型变量选择结果如图3~图5所示。3种组分不同特征波长筛选方法的建模结果如表4所示。
图2 预处理后的近红外光谱
注:A~J依次为中心化、归一化、移动窗口平滑、SG平滑、MSC、SNV、一阶和二阶导结合窗口平滑以及一阶和二阶导结合SG平滑处理后的光谱。
图3 小麦粉水分SPA-PLS法选择的变量
图4 小麦粉水分CARS-PLS法选择的变量
图5 小麦粉水分MCUVE-PLS法选择的变量
表4 不同特征波长筛选算法的建模结果
采用SG-CARS-PLS算法特征提取的变量数为33,预测集的R2经过CARS算法的特征筛选提升到0.9215,RMSEP降低到0.0996。与未进行特征筛选直接建模的结果相比,采用该方法的预测精度有了一定的提升,说明CARS算法成功剔除了数据中的干扰信息,所选变量基本上涵盖了所有特征点,使得模型精度进一步提高,取得较为理想的建模效果。对于灰分和面筋含量,直接利用预处理后的数据进行建模的预测效果更好。预测集的决定系数R2分别为0.8718和0.7609,均方根误差分别为0.0731和1.1194,与原始数据的建模结果相比均有较大提升。特征波长筛选算法并未使这两个组分的模型精度再次提高,可能是由于样本量较少,使得组分含量分布范围较窄,部分特征在波长筛选的过程中被削弱,导致特征提取后的数据建模效果不佳,2种组分的模型还存在一定的提升空间。小麦粉3种组分的建模效果均较为理想,经过样本划分、预处理和特征波长筛选后的模型预测效果得到进一步提升,3种组分最优模型的RPD分别为3.57、2.79和2.05,模型具有一定的可靠性。
3 结论
本研究利用近红外光谱技术实现了对小麦粉品质的定量检测。通过比较3种样本划分方法、8种预处理方法和3种特征提取算法对模型的影响,结合内部交互验证和外部验证,筛选出最佳的PLS定量模型,成功预测小麦粉的水分、灰分和面筋含量。实验结果显示,数据处理方法有效降低了预测误差,进一步提高了模型准确率,提供模型优化新思路。后续进一步优化灰分和面筋的模型,扩充样本数据,并进行实验模型验证,以期将该模型用于小麦粉品质快速检测的生产线上。




 微信号
微信号