信息摘要:
饲料是畜牧生产的物质基础,饲草原料和饲料产品营养价值的检测与评估是饲料生产中的重要环节,面对饲草资源中粗蛋白含量低和大量依靠进口饲料的局面,大豆作为...
饲料是畜牧生产的物质基础,饲草原料和饲料产品营养价值的检测与评估是饲料生产中的重要环节,面对饲草资源中粗蛋白含量低和大量依靠进口饲料的局面,大豆作为优质的高蛋白豆科饲草是畜牧业生产利用的重要资源。不同青饲大豆及其不同刈割期的饲用品质参数可以评价青饲大豆的饲用性能,但目前主要以化学方法进行检测,过程繁琐,试验周期长、易造成人为操作误差,且青饲大豆主要饲用品质指标的光谱快速检测尚属空白,亟待开发和利用。鉴于近红外光谱快速分析技术在检测领域及饲料分析中的广泛应用,利用近红外光谱分析技术在950~1 650nm范围内收集不同大豆品种不同刈割时期的全株样品光谱,对样品的主要饲用品质参数粗蛋白(CP)含量、中性洗涤纤维(NDF)含量和酸性洗涤纤维(ADF)含量三个指标按国家标准或行业标准的化学方法进行检测,得到的150份样品的品质数据按3∶2分为校准集和验证集。通过一阶求导(NW1st)、二阶求导(NW2nd)、标准正态变量变换方法(SNV)、去趋势算法(DE-trending)4种不同光谱预处理方法中的一种或多种处理的组合,结合偏最小二乘(PLS)回归算法建立了青饲大豆三个主要品质参数CP,NDF和ADF含量的预测模型。通过比较回归模型中的校准集和验证集中决定系数(R2)和均方根误差(RMSE)得出,NW1st+DE-trending+SNV+PLS处理后所建立的模型效果最好,青饲大豆CP含量模型中的校准集的RC2和验证集的RP2分别为0.96和0.95,NDF含量模型中的RC2和RP2分别为0.90和0.89,ADF含量模型中的RC2和RP2分别为0.94和0.93。通过验证集对预测模型的检验分析进一步证实了该模型的准确性和稳定性,形成了一种便于青饲大豆品质检测的近红外光谱(NIRS)快速分析法。随着青饲大豆品质参数数据量的增加,将不断完善青饲大豆品质检测模型,该方法不但扩大了近红外光谱仪对饲草资源品质的检测类别与范围,而且准确高效,有利于高蛋白优质饲草资源的开发和有效利用。
饲料是畜牧生产的物质基础, 随着畜牧业的快速发展, 优良饲草成为畜牧业生产的重要资源, 对饲草原料和饲料产品营养价值的检测与评估是饲料生产中必不可缺少的重要环节, 饲料生产中的质量控制及其营养成分的快速分析越发重要。 饲料品质的管理与科研的主要手段仍沿用传统经典的化学分析方法分析饲料及饲草的常规组分及营养成分, 这些传统的分析方法存在分析周期长、 方法复杂、 试剂消耗, 污染环境和有损健康等缺点。 因此, 建立快速准确且简便绿色的分析方法十分必要。
近几年, 近红外光谱(NIRS)快速分析技术在分析化学和检测领域得到广泛应用。 NIRS技术适合于多组分的定性和定量分析, 具有制样简单、 无污染、 操作简单、 检测速度快、 稳定性好、 在线分析等优点[1][2]。 基于待检样品在近红外光谱区域的光学吸收特性, 通过国标化学方法对样品的化学成分含量与其近红外反射光谱进行回归分析, 建立模型, 从而对同类及其相似类型的未知样品进行品质指标的检测与分析。 NIRS分析过程一般包括扫描样本, 获得近红外光谱数据; 采用国标分析测试法测定样本的组分或含量数据; 建立并优化两者的函数关系, 预测模型。 NIRS建模的方式包括主成分分析、 多元线性回归、 偏最小二乘(partial least squares, PLS)、 人工神经网络(artificial neural networks, ANN)等。 在众多光谱数据分析中, PLS是利用频次高、 反演精确的一种建模方法, 是在多元线性回归的基础上发展起来的一种回归方法[3][4]。 PLS利用全部光谱信息进行矩阵分解和回归交互分析。 基于PLS算法, 衍生出多种模型, 如多模型PLS、 移动窗口PLS建模, 及PLS与ANN联合的PLS-BP预测模型, 用来检测饲料样品水分、 蛋白质、 灰分、 磷含量。
饲料检测是NIRS技术应用最早的领域之一, 且发展迅速, 应用广泛, 马蹄草营养成分的NIRS检测[5], 便携式光谱仪实时测定饲料中蛋白质、 粗纤维和淀粉等组分的研究[6][7], 以及建立动物粪便中性洗涤纤维(NDF)的近红外光谱校准方程, NIRS技术被认为是准确测定牧草化学成分和消化率参数的重要工具[8][9]。 目前, 关于饲料中粗蛋白(CP)含量、 粗纤维、 粗脂肪等NIRS快速测定已有国家标准(GB/T 18868—2002), 解决了饲料企业的品质检测和产品开发的需求。 现有的NIRS技术主要用于玉米、 豆粕、 鱼粉等饲料原料及浓缩饲料、 配方饲料等成品饲料的常规营养组分的性质与含量分析, 以及饲料营养价值的快速评定。 然而, 作为饲草资源的青饲大豆全株品质检测的NIRS技术亟待开发和利用。 目前, 我国饲草存在产量低、 品质差, 粗蛋白质含量<15%, 优质饲草资源稀缺等问题, 大豆作为短日照作物, 其光周期反应较为敏感, 可以利用大豆这一特性进行南种北移, 作为一种新型的青饲豆科资源加以利用, 有利于解决饲草蛋白含量低的问题, 进一步推进二元种植结构到粮食、 经济、 饲料作物的三元结构的粮改饲政策。 本研究对青饲用不同大豆品种不同时期的整个植株进行粗蛋白(CP)含量、 中性洗涤纤维(NDF)含量和酸性洗涤纤维(ADF)含量进行检测, 采用不同的光谱预处理方法和变量选择方法来优化模型, 利用近红外光谱建立含量分析回归模型, 形成一种便于青饲大豆全株品质检测的NIRS快速分析法。
1 实验部分
1.1 样品制备
利用大豆光周期的植株生长特性, 选用来自于东北春夏大豆、 黄淮海夏大豆、 南方春大豆、 南方夏大豆几个生态区域的50个大豆品种样本作为青饲大豆全株品质参数检测的品种试验, 取样时期为盛花期、 鼓粒初期、 鼓粒初期5 d后去荚处理三个主要青饲大豆全株的利用方式, 三次重复, 三种方式的地上部分植株经65 ℃烘干至恒重后粉碎待测。 每个样品的CP, NDF和ADF含量分别按照国家标准(GB/T 6432—2018, GB/T 20806—2006)和行业标准(NY/T 1459—2007)的方法检测, 每个品质参数共得到150个数据。
1.2 近红外光谱收集
利用近红外光谱成像仪(DA7250, Perten, Sweden), 光谱范围为900~1 700 nm, 实际工作的光谱波长范围为950~1 650 nm, 波长精度<0.3 nm, 光谱分辨率为7 nm, 二极管间距(像素间距)3.1 nm·像素-1, 检测器为InGaAs, 电温控制冷处理, 256像素, 内置线性参考光源。 可驱动载有样本的旋转杯, 用来控制系统运行的计算机以及近红外成像系统采集软件。 为保证获取光谱的一致性, 检测温度为15~25 ℃, 样品厚度一致为5 mm, 湿度范围为30%~70%, 每个样品至少扫描三次以获得光谱数据, 所有光谱曲线的波形呈现相同的趋势(图1), 在全波段范围内进行青饲大豆全株品质指标的模型建立。
图1 原始光谱曲线
Fig.1 Original spectral curve
1.3 光谱数据处理
建立CP, NDF和ADF含量的定量识别模型时, 将150个数据集按3∶2比例划分为校准集和验证集。 为提高光谱分辨率, 去除样品表面颗粒不均匀带来的杂散光等, 光谱预处理主要采用一阶导数直接差分法求导法(NW1st)、 二阶导数直接差分法求导法(NW2nd)、 标准正态变量变换法(standard normal variate transformation, SNV)和去趋势算法(De-trending)的一种或几种方法组合进行比较分析。 NW1st和NW2nd对光谱进行基线校正和光谱分辨预处理; De-trending算法是为了消除漫反射光谱的基线漂移, 将原始光谱的吸光度和波长拟合成一条趋势线, 再从原光谱中减掉趋势线; SNV主要是用来消除颗粒大小不均匀和表面非特异性散射。 光谱定量建模分析为多元校正, 在物质浓度与光谱之间建立一种定量关联关系。 PLS集合主成分分析、 典型相关分析和多元线性回归分析3种分析方法的优点, 利用响应矩阵提取出反映数据变异的最大信息, 具有预测功能, 建模性能更优越[10]。 鉴于PLS的建模优势和所用光谱仪参数的匹配度, 利用PLS法, 首先对光谱数据进行运算, 求取主因子或隐含变量, 再根据主因子或隐含变量的累积贡献率得分值, 以及化学指标数据变量, 建立模型。 通过不同预处理后的全光谱结合PLS建立的模型效果图, 利用校准集和验证集的决定系数(R2)和均方根误差(RMSE)比较分析出适合的光谱预处理建模方法, 用于青饲大豆全株主要品质指标的快速检测。
2 结果与讨论
2.1 样品化学值分析
从表1中各指标的最大值、 最小值和标准差值可以看出, 作为青贮饲草资源的不同大豆品种在不同取样时期的CP, NDF和ADF含量的变化幅度比较大, CP含量为11.21%~22.79%, NDF含量为41.02%~63.48%, ADF含量为25.00%~42.51%, 数据覆盖面较大, 样品化学值具有一定的代表性。
表1 样品中主要饲用品质指标的含量统计(%)
Table 1 Content statistics of main forage quality indexes in samples(%)
指标 |
最大值 |
最小值 |
平均值 |
标准差 |
CP |
22.79 |
11.21 |
16.21 |
2.04 |
NDF |
63.48 |
41.02 |
51.25 |
5.02 |
ADF |
42.51 |
25.00 |
33.88 |
4.5 |
2.2 全波段模型效果评价
为了提高预测模型精确度, 以往研究多关注不同光谱处理条件的组合、 不同定量建模分析以及数学方法的应用上, 但实际经验证实, 光谱仪的检测精度、 光谱收集过程的条件控制, 以及化学值测量的准确度才是建立校准模型的基础和关键。 为准确定量分析青饲大豆植株的饲用品质, 将数据分为校准集(R2C
, RMSEC)和验证集(R2P
, RMSEP)分别建立了NW1st, NW1st+DE-trending, NW1st+DE-trending+SNV, NW2nd+DE-trending+SNV四种光谱预处理的PLS模型。 通过比较校准集和验证集的R2和RMSE,R2越接近1, 说明回归效果显著, RMSE越接近0, 说明模型具有较好的稳定性和预测能力。
表2 不同预处理方法的青饲大豆全株主要品质指标的模型结果
Table 2 Model results of main quality indexes of whole plants of forage soybean with different pretreatments
|
预处理 |
CP |
NDF |
RMSEC |
|
RMSEC |
R2C |
RMSEP |
R2P |
RMSEC |
R2C |
RMSEP |
R2P |
RMSEC |
R2C |
RMSEP |
R2P |
|
NW1st |
0.67 |
0.93 |
0.73 |
0.92 |
1.97 |
0.87 |
2.13 |
0.85 |
1.23 |
0.93 |
1.34 |
0.92 |
NW1st+DE |
0.54 |
0.96 |
0.61 |
0.95 |
1.72 |
0.90 |
1.89 |
0.87 |
1.20 |
0.93 |
1.30 |
0.92 |
NW1st+DE+SNV |
0.49 |
0.96 |
0.55 |
0.95 |
1.74 |
0.90 |
1.87 |
0.89 |
1.10 |
0.94 |
1.20 |
0.93 |
NW2nd+DE+SNV |
0.49 |
0.96 |
0.56 |
0.96 |
1.71 |
0.91 |
1.94 |
0.88 |
1.23 |
0.93 |
1.32 |
0.92 |
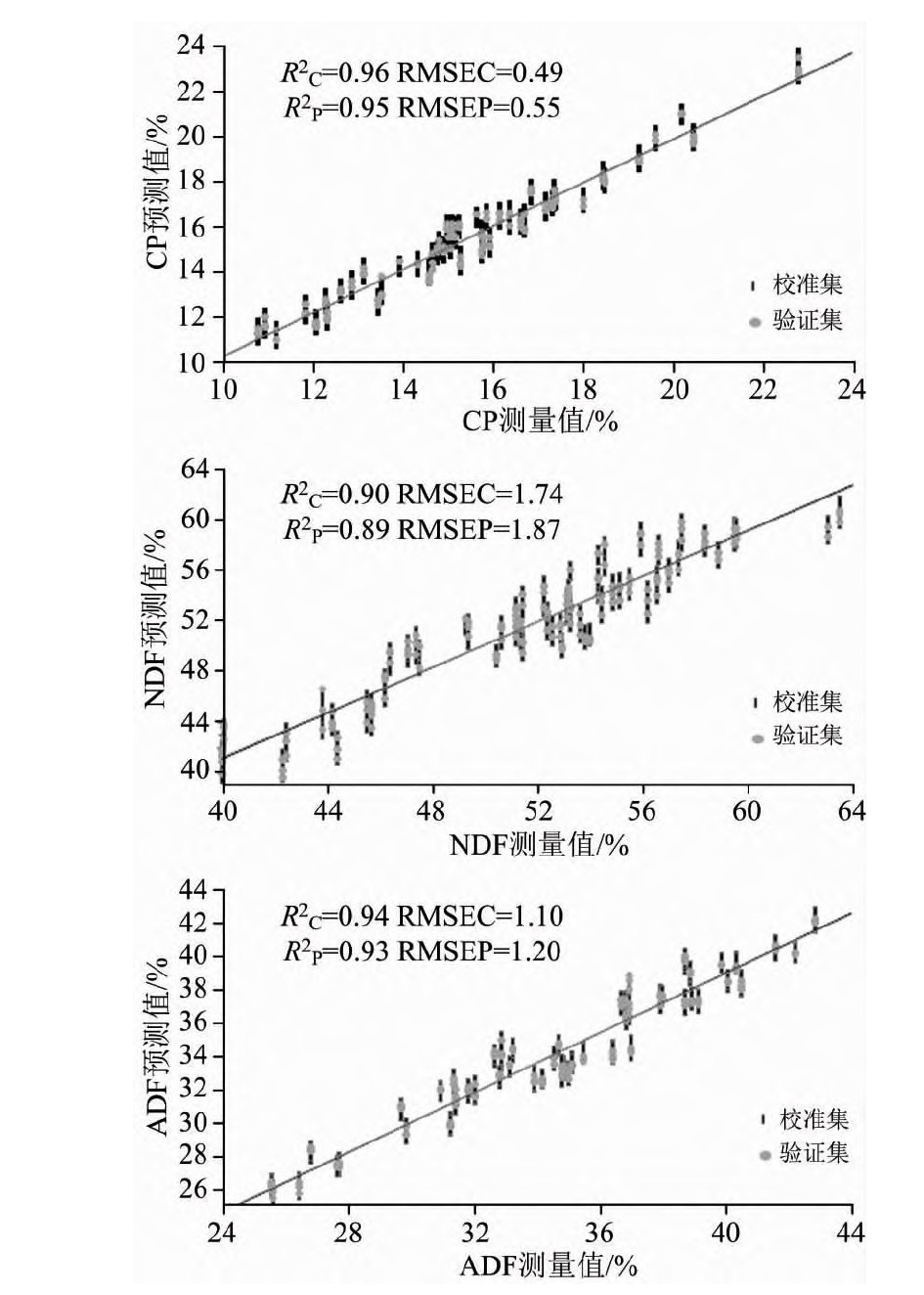
图2 NW1st+DE-trending+SNV处理的青饲大豆品质PLS模型
Fig.2 PLS model of forage soybean quality by NW1st+DE-trending+SNV treatments
从不同预处理方法对青饲大豆全株主要品质指标的模型分析结果可以得出(表2), NW1st+DE-trending+SNV处理的模型中CP含量的R2C
和R2P
分别为0.96和0.95, 且RMSEC和RMSEP值较其他三个处理低, 分别为0.49和0.55; NW2nd+DE-trending+SNV处理中CP含量的R2C
和R2P
均为0.96, 但RMSEP值为0.56, 高出0.01, 说明NW1st+DE-trending+SNV的PLS模型用于检测CP含量的效果好于他处理, 从NW1st+DE-trending+SNV处理的青饲大豆全株CP含量PLS模型中可以看出(图2), 校正集和验证集的回归直线基本重合。 NDF含量模型中(表2), NW1st+DE-trending+SNV的R2C
和R2P
分别为0.90和0.89, RMSEC和RMSEP分别为1.74和1.87, 其RMSEP值相比其他处理最低, 且校正集和验证集的回归直线基本重合; ADF含量模型中, NW1st+DE-trending+SNV处理的R2C
和R2P
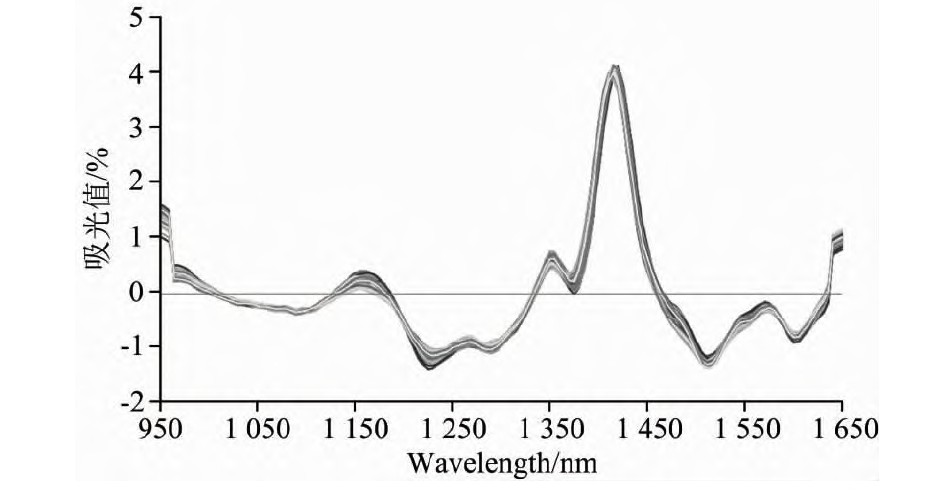
最高, 分别为0.94和0.93, 其RMSEC和RMSEP最低, 分别为1.10和1.20, 相比于NW2nd+DE-trending+SNV处理低0.12~0.13。 综合比较CP, NDF和ADF三个含量指标, NW1st+DE-trending+SNV光谱预处理的PLS模型效果较好, 更稳定更准确(图2)。 经过NW1st+DE-trending+SNV这三种光谱预处理组合的方法, 原始光谱曲线变得平滑, 曲线的噪声、 基线漂移、 共线性现象消除效果较好(图3)。 采用NW1st+DE-trending+SNV的PLS模型检测青饲大豆全株的主要饲用品质指标。
图3 NW1st+DE-trending+SNV处理的全光谱曲线图
Fig.3 The full spectrum curve after NW1st+DE-trending+SNV treatments
3 结 论
利用近红外光谱分析仪获得稳定有效光谱, 通过国标法或行标法对不同品种不同处理的青饲大豆植株中三个主要饲用品质参数CP, NDF和ADF含量进行定量检测, 采用NW1st, NW2nd, DE-trending和SNV四种光谱预处理方法的不同组合建立品质预测模型, 经比较分析校准集和验证集的R2和RMSE, 得出NW1st+DE-trending+SNV+PLS方法建立的模型优化效果好, 并验证了PLS模型的准确性及稳定性, 随着青饲大豆资源的利用和推广, 其品质检测数据量会随之增加, 将进一步优化模型和补充参数, 使青饲大豆品质的近红外检测方法更加完善。




 微信号
微信号